
Having competed in the AWS AI League 2026 London qualifier and finished third, I wanted to share some practical hints and tips for anyone preparing for the agentic challenge at upcoming AWS Summits, or the virtual events planned for later in the year. These are lessons learned through trial, error, and a fair amount of debugging under pressure.
This post won’t give you a winning solution, that’s for you to build, but it should help you avoid some pitfalls and focus your preparation time on what matters.
Understanding the Challenge
The agentic challenge asks you to build an autonomous AI agent that navigates a dungeon maze, solves challenges, and maximises its score. Your agent uses Amazon Bedrock as its brain, with AgentCore providing the orchestration layer. You’ll build Lambda tools, configure guardrails, set up memory, set-up sub-agents, and write a supervisor prompt that ties it all together. If you have time you might even fine-tune a model or two.
The key is that this isn’t just about getting the right answer, it’s about doing so efficiently. Minimising token usage, minimising loss of lives, and successfully answering as many challenges as is possible in the time all factor into your final score.
Architecture Overview
Your agent system has several components that work together:
- Supervisor prompt - the instructions that guide your orchestrator agent’s behaviour
- Lambda tools - custom functions your agent(s) can call (for example pathfinding, code execution, web scraping)
- Guardrails - content filters that must block specific content, without blocking legitimate questions
- Memory - AgentCore Memory that persists context across challenge interactions
- Sub-agents - specialist agents that handle specific task types
The workshop walks you through setting all of these up. Where you differentiate is in how well you optimise each component. You can get ahead of the game by reviewing the workshop documentation in advance, although AWS are regularly iterating the challenges in the game so don’t expect this to be 100% what you’ll face on the day.
Tip 1: Pathfinding is Your Foundation
The pathfinding tool is the first thing your agent uses and arguably the most important. A good path maximises points while minimising time, and is flexible enough to deal with the first round (often a large map with sufficient time to complete all challenges), as well as finale rounds where there may be insufficient time to complete all challenges and will have to make decisions on what is achievable in the allotted time.
Things to consider:
- Strategy modes - think about when to prioritise score vs. when to prioritise reaching the treasure quickly
- Tile awareness - your pathfinder should understand which tiles are dangerous (spikes cost lives), which are valuable (coins, challenges), and which are impassable and immediately end the game (walking into walls and leaving the board)
- Time constraints - finale levels may have tight timers. A shorter path that reaches the treasure is often better than a longer path that collects every coin but runs out of time
Here’s an example of a qualifier round map - a large grid with corridors, challenges, and a treasure to reach, with a 5 minute plus time, plenty long enough to complete everything: -
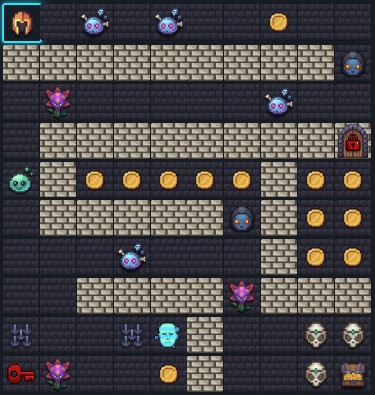
And here’s a finale stage - notice the tighter layout and different challenge distribution that demands a different strategy, as you’re only given around 2 minutes to complete the challenge: -

Tip 2: Token Economy Matters More Than You Think
Every token your agent outputs costs you points. The scoring formula includes a token bonus that rewards concise responses. This means:
- Suppress verbose reasoning - if your model outputs long
<thinking>blocks, you’re burning points - Direct answers win - for simple questions like “What day comes after Monday?”, the ideal response is just “Tuesday”, not a paragraph explaining the days of the week
- Tool calls should be purposeful - calling a tool when you don’t need to wastes tokens and time
- Fine-tuned models reduce token penalty - the token penalty is reduced for every fine-tuned model you have in your architecture, up to the maximum allowed per competition (which varies)
Your prompts are the primary lever here. Clear, directive instructions about output format make a significant difference.
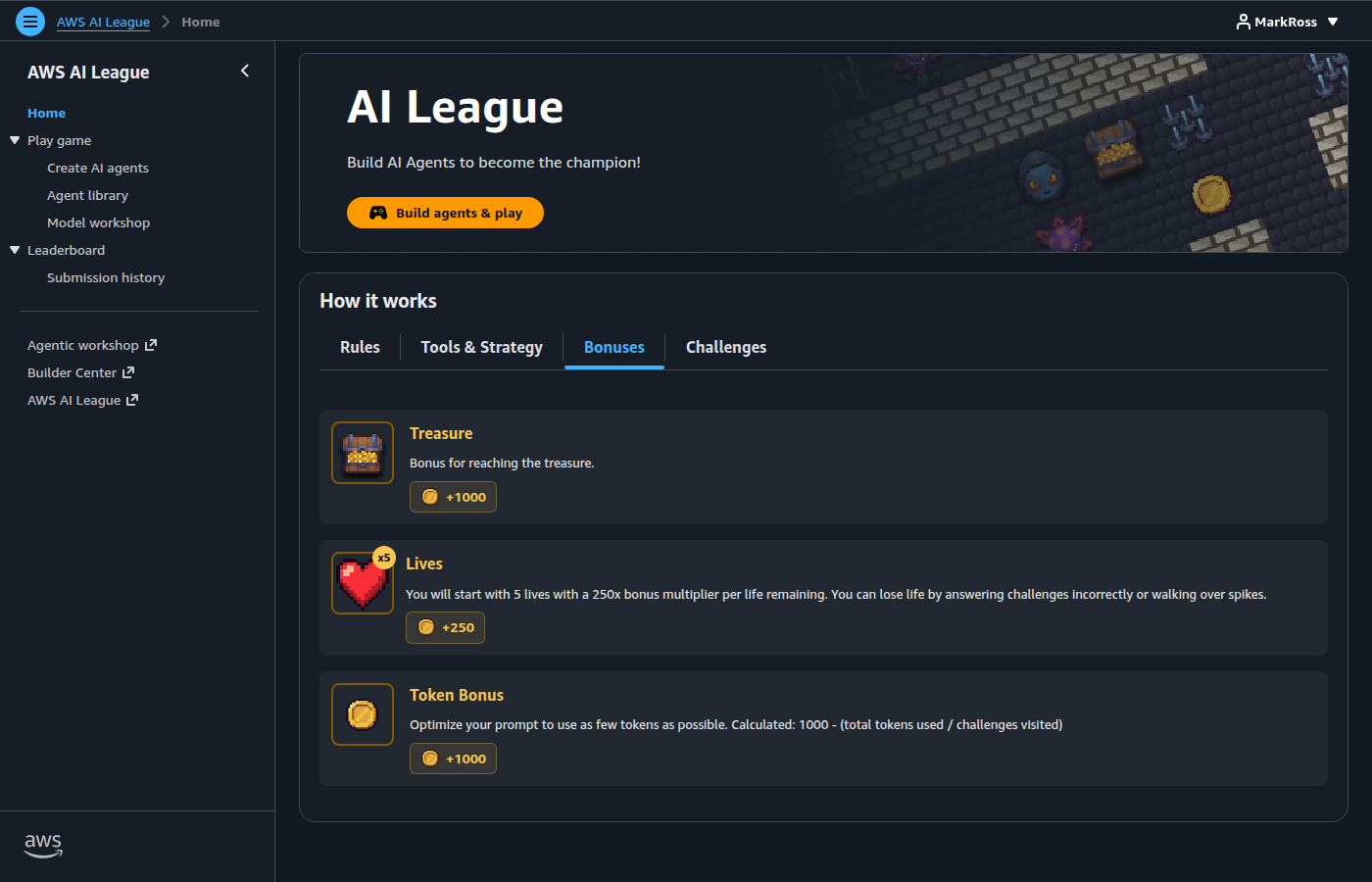
The scoring bonuses break down as follows:
- Treasure bonus — 1000 points for reaching the treasure
- Lives bonus — 250 points per life remaining (start with 5, so max 1250)
- Token bonus — calculated as: 1000 - (total tokens used / challenges visited)
Tip 3: Guardrails Need Precision
The Violent Violet challenge tests whether your guardrail correctly blocks specific content. The tricky part is that some blocked topics could overlap with topics that need to be allowed, for example you may need to block topics relating to transplanting plants, whilst allowing questions related to ’transplants’ within a healthcare context.
Key considerations:
- Don’t over-block - if your guardrail is too aggressive. This costs you points on other challenges
- The guardrail must actually fire - the game checks whether the guardrail intervened, not whether your agent provided back a prompt that refused to answer the question. If your supervisor prompt tells the agent to refuse, but the guardrail never triggers, you’ll fail the challenge
Tip 4: Memory is a Must
AgentCore Memory gives your agent context across interactions. This is essential for challenges like Memento, which ask questions about the map state (e.g. how many tiles contain a certain challenge), and for key/door challenges where you need to remember a code from the key tile, and present it when you get to the door tile.
Things I learned:
- Memory doesn’t work on cold start - at the time of writing the first time you enable memory it doesn’t seem to work correctly, I’ve flagged this to AWS so hopefully they can fix. From your perspective just don’t be surprised if it’s only on the 2nd+ runs that you start answering Memento questions correctly
- The map context is your friend - questions like “How many c5 challenges are on the map?” can be answered by counting tiles in the map data that was provided in the initial prompt
Tip 5: Know Your Challenge Types
Each challenge type has a different optimal approach:
| Challenge | What It Tests | Key Insight |
|---|---|---|
| c1 (Violent Violet) | Guardrail blocking | Must be blocked by the guardrail, not by prompt engineering |
| c2 (Blue Brain) | Code execution | Use your code interpreter tool — don’t let the LLM guess at maths |
| c3 (Memento) | Memory/map awareness | Answers come from the map data, not general knowledge |
| c4 (Dark Prophet) | Web scraping | Must fetch the actual URL and extract the answer |
| c5 (Bonehead) | General knowledge | Keep answers short — token efficiency is key here |
| c6 (Boss) | Multi-skill combo | Requires combining multiple capabilities in one challenge |
| c7 (Coins) | Free points | No prompt needed — just walk over them. Plan your path to collect as many as possible |
| c8 (Spikes) | Trap avoidance | Costs a life with no reward. Your pathfinder should avoid or minimise these |
| c17 (Distraction) | Token waste trap | These try to make your agent output lots of tokens. Resist! |
| c18 (Healthcare API) | Structured data extraction | Must extract patient data into a precise format |
| c40–c43 (Keys) | Memory storage | Collect the key code and remember it for the matching door |
| c30–c33 (Doors) | Memory recall | Recall the key code from earlier — wrong answer costs 5 lives, so you must visit the relevant key first! |
Understanding what each challenge actually tests helps you build the right tools and prompts.
Tip 6: The Supervisor Prompt is Everything
Your supervisor prompt is the single most impactful thing you can optimise. It controls:
- Which agent(s) and tool(s) gets called for which challenge type
- How verbose the agent’s responses are
- Whether the agent wastes time on unnecessary reasoning
A few principles that helped:
- Be directive, not suggestive - be explicit about what you want, don’t leave things to chance
- Map challenge types to tools explicitly - tell the agent exactly which tool to use for which scenario
Tip 7: Test Iteratively, Not Just Once
Build a practice loop:
- Run your agent against the known map
- Review the game events - which challenges did it win/lose?
- Check the logs — why did it fail? Wrong tool? Timeout? Bad answer?
- Adjust and repeat
The AWS account you’re given has CloudWatch logs for everything. Use them, don’t guess at what went wrong.
Here’s what a combat log extract looks like from a real game run — you can see the agent calling tools, answering challenges, and the scoring in action:
FoundChallenge — a Red Key
AskChallenge (c40): Red Key 1 is: open
WinChallenge (c40) +50pts ✓
FoundChallenge — a Red Door
AskChallenge (c30): What is red key 1?
LoseChallenge (c30) -5♥ ✗ ← Failed to recall the key! Game over.
Notice how the Red Door failure cost 5 lives and ended the game — the agent collected the key but failed to recall the code when it reached the door. This is exactly the kind of issue you catch by reviewing combat logs and then improving your memory configuration.
Tip 8: Fine-Tuning is likely a Bonus, Not a Requirement
The competition awards bonus points for using custom fine-tuned models. This is powerful but time-consuming. If you’re short on time, of the three finalists in London two of them didn’t fine-tune a model, I suspect due to time constraints. Fine tuning will become more important over time as people become experienced and turn up to events with a ‘kit bag’ from previous events, or if the virtual events are long running.
At the time of writing the only model you can fine-tune with is Qwen 0.6B. A very small model and it’s surprisingly hard to get it to stop outputting <thinking> tokens, so make sure you account for that in your fine-tuning.
If you do fine-tune:
- Start small - don’t rush into a complex task like pathfinding, try a simpler challenge for fine tuning, nail your process and work up in complexity from there
- Beware catastrophic forgetting - AWS recommend a two step process, of fine-tuning for tool calling, then fine-tuning for ‘faithfulness’ (returning the tool output exactly), getting the balance right is tricky, as too much of the latter may make the model forget the former
- Quality over quantity - a focused dataset of 400 examples beats a noisy dataset of 4000, a small validation dataset that is unique and contains no examples that appear in your training dataset is key
- Reward shaping within your reward function is key - the fine-tuning job needs to get positive reinforcement from your reward function. If you have scoring bands that are too wide, draconian penalties for wrong behaviour etc. these things can all stop the training progressing positively, because the training job doesn’t know what good looks like. If you’re seeing a nice upward trajectory in your training graphs then you’re on the right lines, if not think about how you can better shape your reward function
- Test in production - training metrics don’t always match real-world behaviour. Always validate with actual game runs
- Tool schema is non-deterministic - your fine tuning needs to call a tool name, but you cannot determine it in advance (AWS use AI to auto-generate it), so deploy your tools before trying to create fine-tuning models to call them
Tip 9: The Finale is Different
If you qualify for the top 3, the finale format changes things:
- No code changes allowed - your architecture must be robust enough to handle unknown maps, which is great, because it weeds out anyone trying to hardcode things
- You can provide a steering instruction - a short prompt that guides your agent’s strategy for that specific level, e.g. the time allowed, the number of lives etc.
- Speed matters - with a likely shorter time to navigate the map, you want your agent to move decisively, not deliberate
Build flexibility into your solution from the start. An agent that only works on one specific map layout won’t survive the finale, and one that always collects all challenges / coins won’t either - have different strategies you can call via your prompt.
Tip 10: Use AI to Build AI
This is an AI League - using AI tools to help you build your solution is not just allowed, it’s expected. Use coding assistants to help you write Lambda functions, debug issues, and iterate quickly. The workshop gives you limited time, so efficiency in your development workflow matters. I’d strongly advocate to take all the instructions and store them locally so you give any AI agent you choose to use the maximum context to help you perform in the competition.
Final Thoughts
The AWS AI League is genuinely fun and educational. Even if you don’t place in the top 3, you walk away having built a working multi-agent system with real AWS services - that’s practical experience you can apply immediately.
The competition rewards preparation, but also adaptability. The maps change, the questions vary, and the finale throws curveballs. Build something robust, test it thoroughly, and enjoy the ride. Make sure to connect with fellow competitors, whilst you might be adversaries for a few hours all competing for the top prize, you’ll likely make new friends and all exchange ideas - a rising tide raises all ships!
Good luck at your next AWS Summit qualifier, or the virtual league. See you on the leaderboard.
Want to join the AWS AI League? Visit the AI League Page for details on upcoming qualifiers and how to apply for an enterprise event for your company. Follow the league in the AWS AI League Builder Space for updates, or join the AWS AI Community to connect with fellow competitors.